


Text version 👇
The two types of GenAI interactions
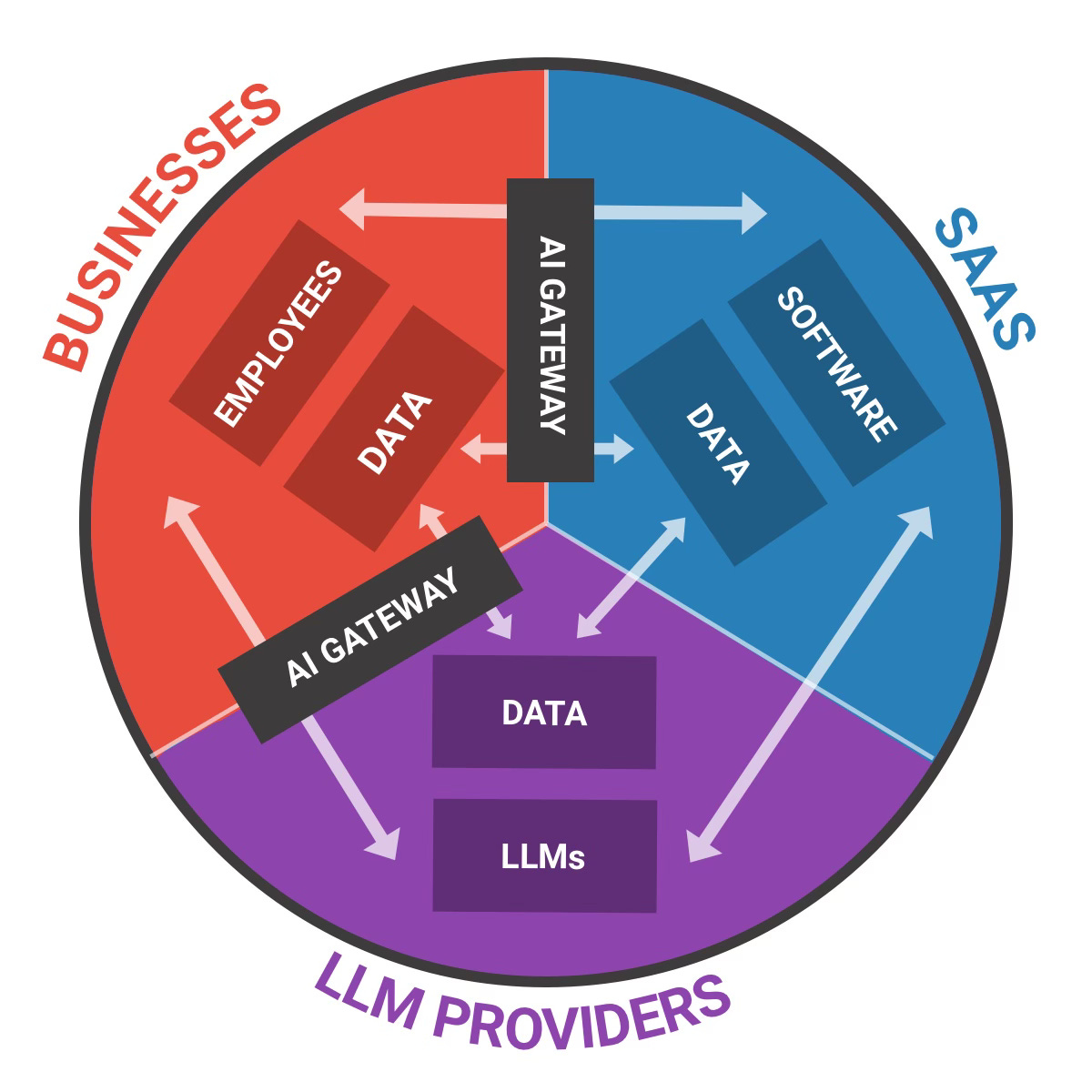
Before we explore the new cybersecurity threats that GenAI creates, let’s visualise how businesses interact with the software and LLMs they rely on.
On my camembert (I can’t help, I’m French) you can see three actors:
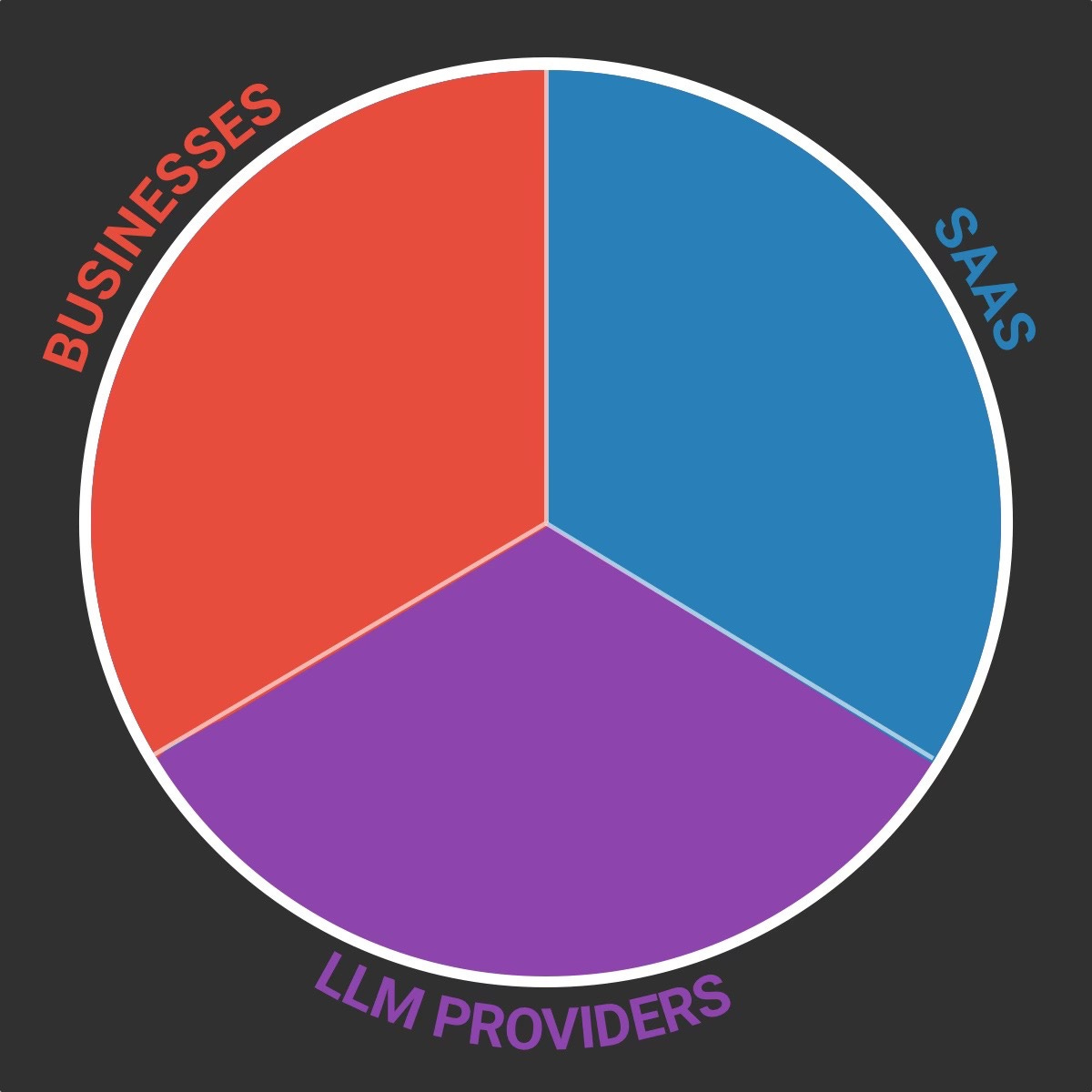
Businesses: Self-explanatory.
SaaS: The software products that provide GenAI functionalities to businesses (SaaS, agents…).
LLM providers: The companies that provide models to both businesses and SaaS (OpenAI, Google, Mistral, Anthropic etc…)
At the core of each of these actors are:
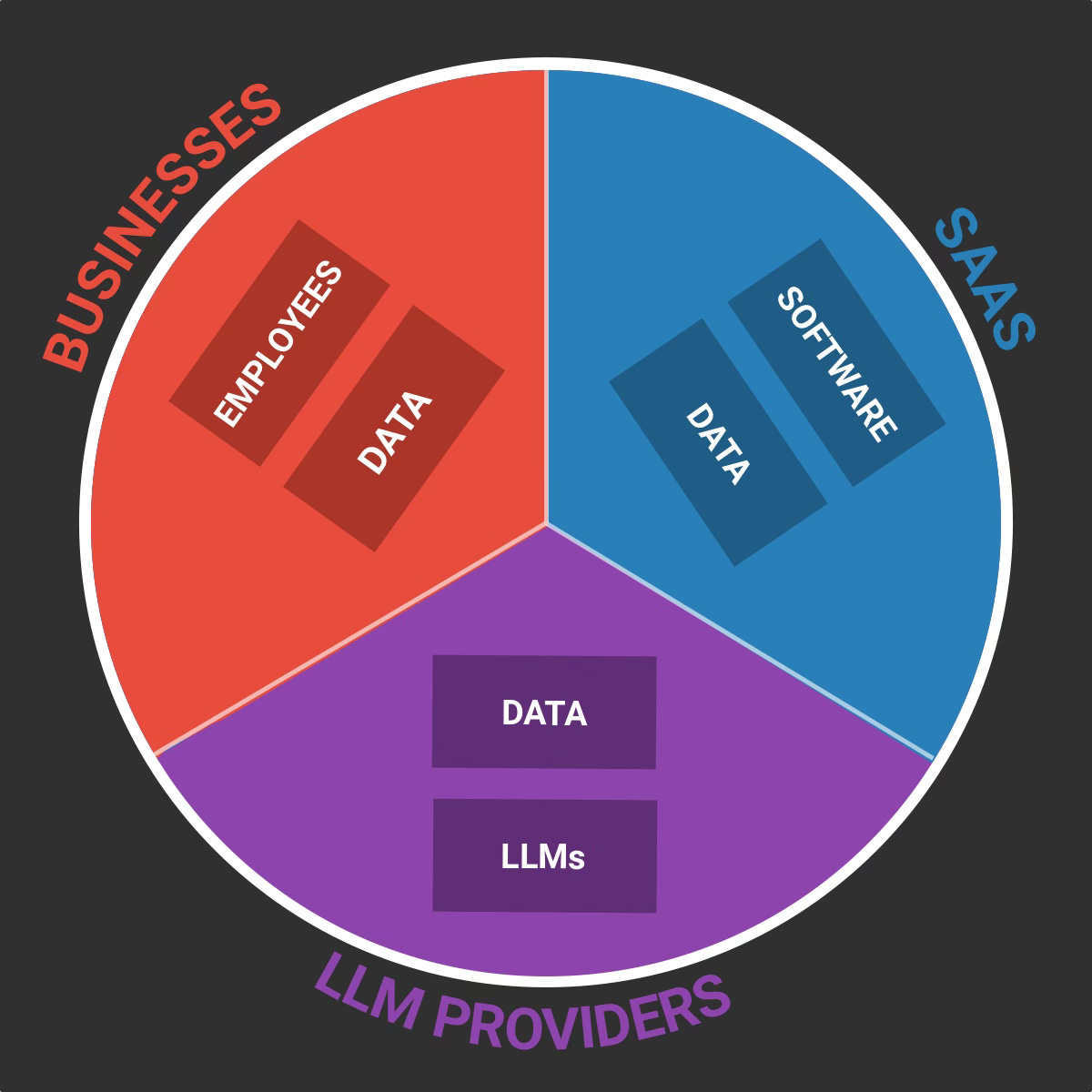
Businesses: Their employees (and customers) layer + their data layer.
SaaS: Their software/application layer (logic, code, workflow…) + their data data (hosted customer data, product usage data, proprietary data…).
LLM Providers: Their models + their data layer (training data, customer data, usage data etc.).
The first type of GenAI interactions happen through text prompts, which is usually human based (employees, customers, developers etc. prompting LLM apps):
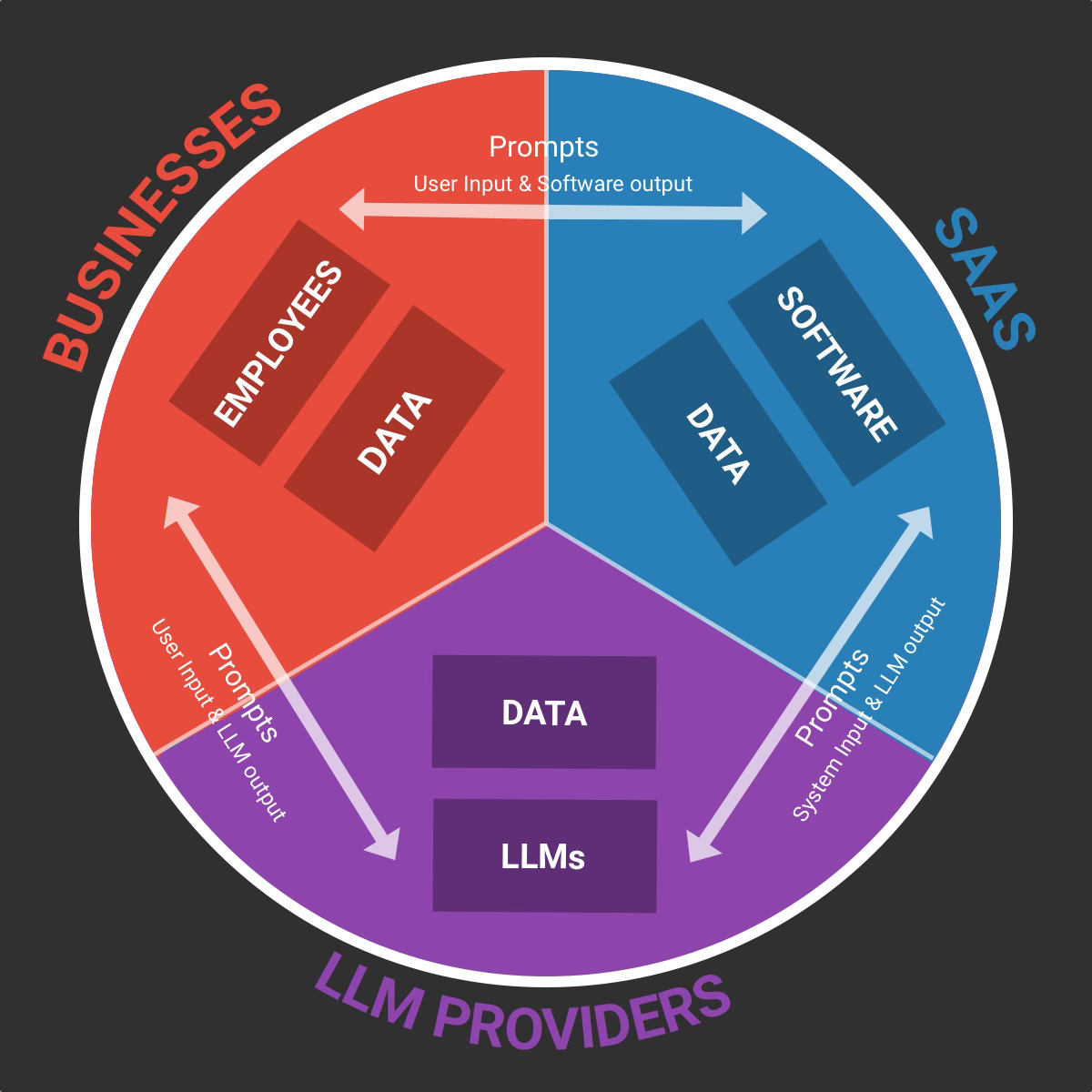
Business <> SaaS: The users/employees write text prompts and software provides output.
Business <> LLM providers: The users/employees write text prompts and LLMs provide output.
SaaS <> LLM Providers: The software writes prompts (often the system prompt + user prompt) to the LLM providers in order to get an output.
The second type of GenAI interactions are the "programmatic ones”, usually happening between machines and through API calls, MCP connections or RAG operations:
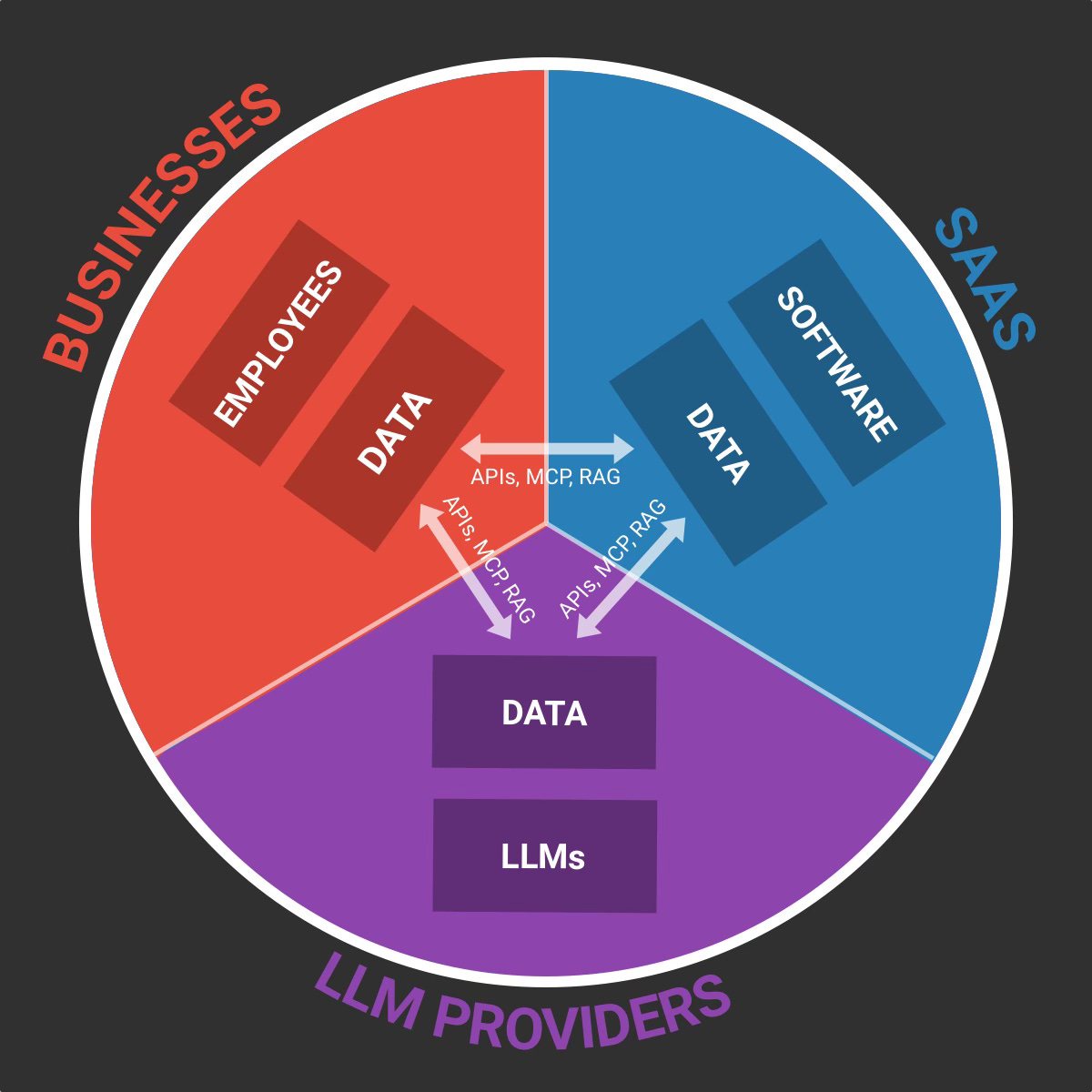
The new GenAI risks & their solutions
With this camembert in mind, it’s easy to visualise where GenAI creates new types of security risks and threats.
Prompt related risks
Direct prompt injection: Malicious instructions are directly written into text prompts to manipulate the output.
Indirect prompt injection: Malicious instructions are hidden in external data (e.g. in website pages, in documents, in emails etc.) that the human user doesn’t see but that the LLM model consumes. Example: Hidden malicious instructions hidden in an email that the human recipient won’t see but that the email agent will.
System prompt leakage: It’s when attackers try to access the Software system prompts.
Improper output handling: It’s when unsafe or unvalidated GenAI outputs are passed to the businesses or software which can create security problems. Basically “output based” risks instead of “input based risks”.
Solutions:
Prompt sanitization: Cleaning and rewriting user prompts to remove malicious instructions.
Prompt input & output validation & filtering: Checking prompts and LLMs output to block unsafe or unintended content.
Model hardening: Strengthening the model itself to resist manipulative prompts.
Prompt system hardening: Securing the hidden system prompts and orchestration logic to prevent leakage or manipulation.
Data related risks
Sensitive data disclosure: When the model exposes personal, proprietary, or confidential information unintentionally.
Data retention: When sensitive business data sent to SaaS or LLM providers is stored longer than expected or without control.
Data used for training: Customer data reused for training may introduce leaks, bias, or harmful behavior into future models.
Solutions:
Privilege management/control: Limit and monitor access rights so agents, users, or apps can only reach the functions and data they truly need.
Autonomy control: Restrict how much independent action an AI system can take without human oversight.
Data sanitization: Cleanse inputs to remove sensitive, malicious, or irrelevant data before processing.
Homomorphic encryption/data tokenization: Protect sensitive information by encrypting or substituting it while still allowing computations.
Integration & workflow related risks
Third-party vulnerabilities: Insecure or malicious external tools (like unsafe MCP servers) can be used as attack vectors.
Denial-of-Wallet: When attackers run up huge API or model usage bills by forcing excessive requests.
Solutions:
Third-party integration & MCP monitoring: Analyze and monitor external tools and MCP servers.
Usage Guardrails: Enforce limits, monitoring, and alerts to prevent uncontrolled API costs.
Model related risks
Unsecure & outdated models: Using models without updates or security patches exposes systems to known exploits.
Vulnerable pre-trained models: Pre-trained models can carry hidden backdoors, biases, or malicious manipulations from their training data.
RAG vulnerabilities: Poorly secured vector databases and embeddings in RAG pipelines can be poisoned by attackers.
Solutions:
Model versioning: Track and manage model updates to ensure secure, consistent, and auditable deployments.
Model scanning & anomaly detection: Continuously check models for vulnerabilities or abnormal behavior.
Model rating: Assign risk scores to models to guide safe adoption and usage.
Red teaming: Test models with adversarial attacks to uncover hidden weaknesses before attackers do.
RAG data validation, sanitization & versioning: Clean, verify, and version retrieval data to prevent poisoning or leaks in RAG pipelines.
Mapping the GenAI cybersecurity solutions
When I looked at the wave of cybersecurity startups tackling these new GenAI threats, the thing that stood out is that unlike other software categories (marketing, design, dev tools…), there aren’t clear, distinct categories of solutions. Instead, most products tackle a mix of threats, each through their own flavor of software. So you end up with a lot of overlaps between products in terms of features.
The only real line of separation I noticed is between two broad models:
All-in-one GenAI Gateways: The Swiss army knives of GenAI security, aiming to cover the broadest range of risks and often addressing the employees.
Use-case focused solutions: Specialized tools built for narrower scenarios or specific personas (often developers).
All-in-one GenAI gateways
Think of an GenAI gateway as a proxy that sits between businesses and the GenAI applications and LLMs they use. Every prompt from and to the business flows through this gateway before it reaches the model.
Because the gateway sees everything, it can defend against a wide range of risks: From prompt injection to unsafe outputs, data leakage, and even “denial of wallet” attacks (e.g. flagging usage spikes per user).
Gateways often provide a single secure interface where employees can type prompts instead of going directly to ChatGPT, Claude, or else. They even let them pick and switch between model providers in one place (kind of an AI model aggregator).
Examples: Prompt security, Lasso, Nexos, Aim.security, Noma Security, Lakera, Pangea, Pillar.
The use-case focused products
On the other hand, some startups focus on specific use cases such as AI reliability, model security or AI red teaming / pentesting (etc.) and hence are closer to specific layers in our camembert (data, model etc…)
Their approach is to focus on a particular slice of the threat landscape, usually under the umbrella of a coherent use case. This is why there’s often overlap between these products in terms of features. For example, prompt injection can be handled at the user level (via input filtering), at the code level or at the model level. So you end up with prompt injection security beeing offered by most tools, even if they don’t have the same overall scope.
Examples: Snyk: (code vulnerabilities), Galileo.ai (AI reliability), Hydrox.ai (evaluation and testing/reliability), ProtectAI (model security), TrojAI (AI firewall and pentesting), HiddenLayer (model security), Archestra (data and MCP security).